An interesting attempt
Preface#
As we all know, WeChat chat databases are encrypted, but they are not impossible to decrypt. Currently, the mainstream methods for obtaining WeChat chat records are through extraction using a rooted phone, or through Apple iTunes backup (non-encrypted, non-intrusive backup and retrieval). There are many articles online about these two methods, and interested readers can search and read them. This article mainly explains an intrusive method that can be done using a PC client.
Process:#
WeChat chat records are stored in a database in sqlite format, with the file extension DB. However, they are encrypted, so the decryption key needs to be obtained first. The decryption key is generally stored in memory, so WeChat needs to be logged in to obtain it.
Decrypting the database:#
By default, WeChat data is located in C:\Users\xxx\Documents\WeChat Files, and the chat record database is located in the wxid_xxxx\Msg\Multi directory under that directory. The chat record file is generally named MSG.db, and if it exceeds 240MB, MSG1.db will be automatically generated, and so on.
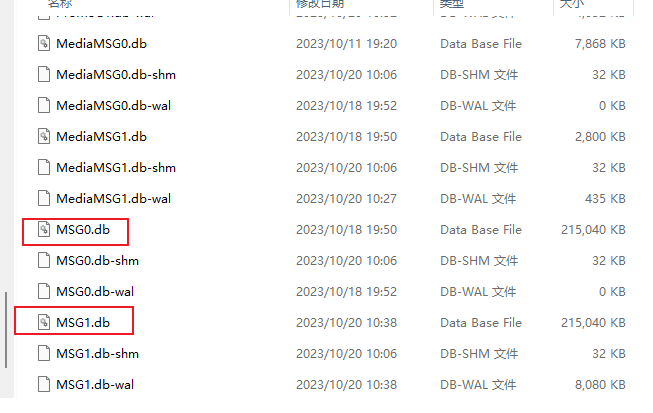
Refer to the GitHub script: https://github.com/0xlane/wechat-dump-rs
Currently, my WeChat version is 3.9.7.25, and it can be decrypted up to this version. The base address updated by the author is also valid.
After executing -a, an unencrypted MSG.db file should be generated in the temp directory.
It can be opened with tools like Navicat.
The chat records are stored in the MSG table, as shown below:
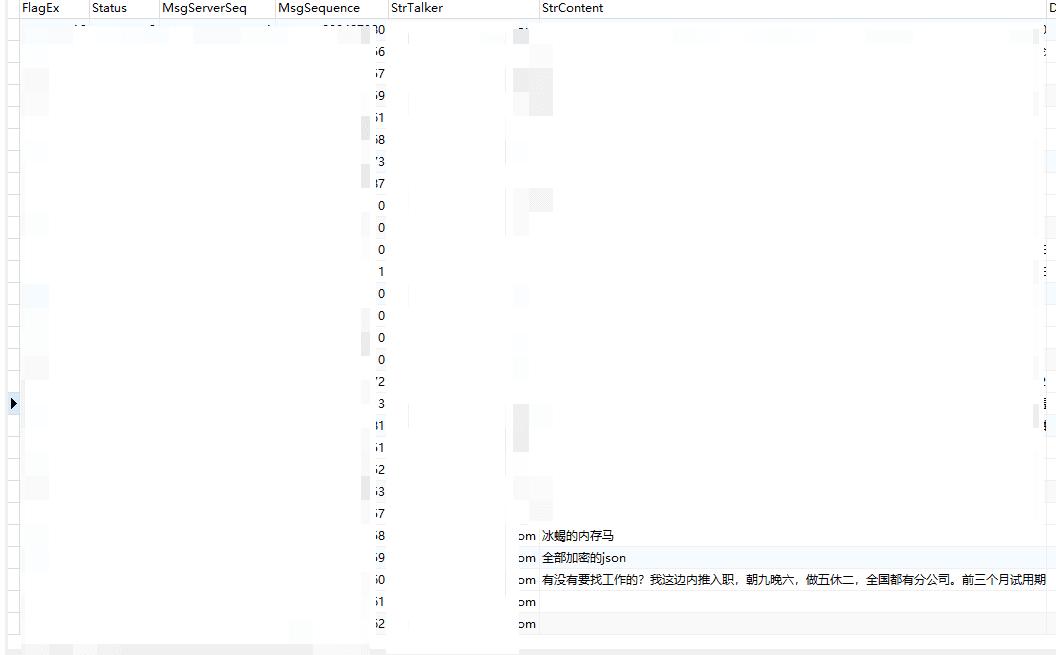
The fields to pay attention to are:
strtalker: Sender's WeChat ID
StrContent: Message keyword
If you don't know the ID, it's also simple. Search for all the chat records you have sent, filter all the matches for that value, and then use the dump. I recommend dumping it to an xlsx spreadsheet.
It's even easier in the spreadsheet. Filter out the row with StrContent and save it to a TXT file, removing all characters and English (not rigorous). I used Python to process the spreadsheet, and the reference code is as follows:
import pandas as pd
import re
# Read the spreadsheet data
df = pd.read_excel('cy.xlsx', sheet_name='Sheet1')
# Define a function to remove non-Chinese characters
def remove_non_chinese(text):
pattern = re.compile(r'[^\u4e00-\u9fa5]') # Regular expression to match non-Chinese characters
return re.sub(pattern, '', str(text)) # Replace non-Chinese characters with an empty string using the regular expression
# Apply the function to remove non-Chinese characters
df['yue'] = df['yue'].apply(remove_non_chinese) # Replace 'column_name' with the column name you want to process
# Save the processed spreadsheet data to a new Excel file
df.to_excel('processed_file.xlsx', index=False) # Replace 'processed_file.xlsx' with the desired file name to save
print("The processed spreadsheet data has been saved to the file processed_file.xlsx.")
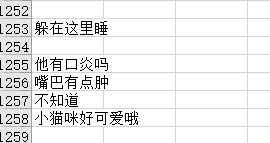
The processed result is roughly like this, for example, my chat record:
Counting word frequency and word segmentation#
Word segmentation requires a Chinese stop word list. I used the HIT stop word list from Harbin Institute of Technology. The project address is as follows: https://github.com/goto456/stopwords/blob/master/hit_stopwords.txt
Here is a code snippet for word segmentation:
import pandas as pd
import nltk
from nltk.tokenize import word_tokenize
from collections import Counter
# Read the document data
df = pd.read_excel('processed_file.xlsx', sheet_name='Sheet1')
# Remove invalid empty rows
df = df.dropna(subset=['yue']) # Replace 'column_name' with the column name you want to process
# Get the document content
documents = df['yue'].tolist() # Replace 'column_name' with the column name you want to process
# Load the Chinese stop word list
with open('hit_stopwords.txt', 'r', encoding='utf-8') as file:
stop_words = [line.strip() for line in file]
# Word segmentation and removal of stop words
tokenized_documents = [word_tokenize(doc) for doc in documents]
filtered_documents = [[word for word in doc if word not in stop_words] for doc in tokenized_documents]
# Calculate word frequency
word_frequencies = Counter([word for doc in filtered_documents for word in doc])
# Create a word frequency DataFrame
df_word_freq = pd.DataFrame(list(word_frequencies.items()), columns=['词语', '词频']) # Replace '词语' and '词频' with the desired column names
# Sort by word frequency in descending order
df_word_freq = df_word_freq.sort_values(by='词频', ascending=False)
# Save the results to a new Excel file
df_word_freq.to_excel('word_frequencies.xlsx', index=False) # Replace 'word_frequencies.xlsx' with the desired file name to save
print("The word frequency results have been saved to the file word_frequencies.xlsx.")
The result is as follows:
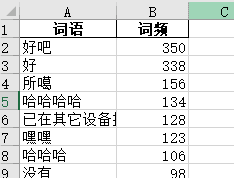
Hahaha, it's quite fun.
Generating word clouds#
There are many projects online that can generate word clouds, but I couldn't find a suitable one for Chinese. I used an online service instead. Interested users can consider using online services, and if you have any good word cloud analysis tools, please recommend them to me.
The content is roughly as follows:

It shows that our chat is really interesting, and every day is filled with laughter (not really).
End#
Once again, thanks to all the authors mentioned in the article and the reference code.
I wish everyone a happy life and love every day.